导读
客户端经常遇到需要对数据进行加密的情况,那应该如何加密,选用什么样的加密算法,是本文想要讨论的问题。
如果把我们的数据比作笔记,那数据加密相当于给笔记本上了锁,解密相当于打开锁看到笔记。而打开锁的钥匙一定是在私人手里的,外人是打不开的。所以数据加密一定有三个关键字:
1.加密
2.解密
3.秘钥
所以有些常见的算法不是数据加密的范围,这个开发需要注意。比如Base64编码,MD5算法。
Base64只是把数据编码,通俗讲只是把原来用汉语写的笔记内容,改成用英语写的内容,只要懂转换规则的任何人都能得到数据。所以老板说把数据加下密,一定不是让你Base64一下或者用其他编码重新编码下,编码算法不涉及到数据安全。
MD5算法也是数据处理的一种方式,更多的被用在数据验证身上。用上面的例子来讲,MD5算法把整本书的内容变成了一句标题,通过标题是没办法推算出整个书讲什么的。因为根本没有解密的步骤,所以也不属于加密算法。
字符编码
计算机的所有数据,最终都是由多个二进制bit(0/1)来存储和传输的,但是怎么从0/1转化成我们可读的文字,就涉及到编码的知识了。下面是基础的编码概念。
ASCII (NSASCIIStringEncoding)
使用一个字节大小表示的128个字符。其中这些字符主要是英文字符,现在很少使用这个编码,因为不够用。ASCII字符占用一个字节。ASCII码表
主要使用到的是英文字母的大小写转换。大写的A~Z编码+32等于小写的a~z。
UNICODE (NSUnicodeStringEncoding)
ASCII只能表示128个字符,对于英文国家来说足够了,对于我们中国来说,我们有几万个汉字不够啊。于是我们创造出了GB2312等等我们自己的字符集。日本也觉得我也不够啊,我也搞个字符集。这些字符集彼此是不兼容的,没办法转换,同样的字符ABCD,我们可能表示好,日本就可能就表示坏。于是程序猿们觉得我要搞个标准,大家都按照标准来。
于是就有了UNICODE编码。它是所有字符的国际标准编码字符集。这个是为了解决ASCII字符不够的问题。同时让所有组织使用同一套编码规则,解决编码不兼容的问题。所以现在通用的编码规则都是UNICODE编码。UNICODE向下兼容ASCII编码。UNICODE最大长度可以到4个字节。不过通常只使用两个字节表示。所以通常认为UNICODE占用2字节数据。
UTF-8 (NSUTF8StringEncoding)
其实UNICODE已经足够使用了,不过因为如果是ASCII表示的字符(比如英文)只需要1字节就可以了,UNICODE表示的话其中一个字节全是0,这个字节浪费了,英语国家的程序猿觉得:我靠,我又不需要那么多复杂的字符,浪费我流量和空间啊,不行!!,于是出现了对UNICODE的转换,也就是UTF-8格式,可以保证原ASCII字符依然用一个字节表示,非ASCII字符使用多个字符表示。
UNICODE到UTF-8的规则如下:
- 按照UNICODE编码的范围,算出需要几个字节,比如1个字节数,2个字数节,3个字节数,4个字节数。具体范围参考下面的图。
- 单字节和ASCII码完全相同,
- 对于其他字节数,字节1的前面用1填充,几个字节数就添加几个
1,后面补一个0。其他字节都用10开头。 - 剩余的位置,按照顺序把原始数据补齐。
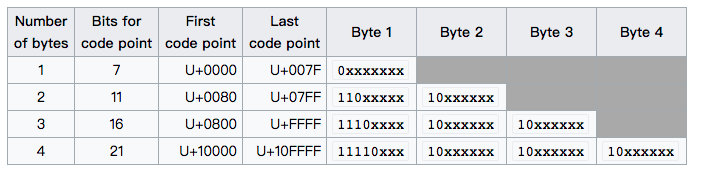
例子:
“汉”字的Unicode编码是0x6C49。0x6C49在0x0800-0xFFFF之间,使用用3字节模板了:1110xxxx 10xxxxxx 10xxxxxx。将0x6C49写成二进制是:0110 1100 0100 1001, 用这个比特流依次代替模板中的x,得到:11100110 10110001 10001001,即E6 B1 89。
对于UTF-8编码的文件,会在文件头写入EF BB BF,表明是UTF-8编码。
UTF-16 (NSUTF16StringEncoding)
UTF-16的编码方法是:
- 如果二进制(流b小于0x10000,也就是十进制的0到65535之内,则直接使用两字节表示。
- 如果二进制流b大于等于0x10000,将b-0x10000的结果中的前 10 位作为高位和0xD800进行逻辑或操作,将后10 bit作为低位和0xDC00做逻辑或操作,这样组成的4个字节就构成了b的编码。
举个例子。假设要算(U+2A6A5,四个繁体字龙)在UTF-16下的值,因为它超过 U+FFFF,所以 2A6A5-10000=0x1A6A5=。
前10位0001 1010 01 | 0xD800 = 0xD896。
后10位10 1010 0101 | 0xDC00 = 0xDEA5。
所以U+ 2A6A5 在UTF-16中的像是D8 96 DE A5。
注:上文参考:精确解释Unicode
在IOS程序里面NSUTF16StringEncoding和NSUnicodeStringEncoding是等价的。
UTF-16大端/小端(NSUTF16BigEndianStringEncoding/NSUTF16LittleEndianStringEncoding)
大小端主要表明了,系统存储数据的顺序。因为UTF-16至少两个字节,这两个字节传输过来后,接收的人需要知道哪个字节是在前,哪个字节在后。然后系统才知道改如何存取。
Unicode规范中用字节序标记字符(BOM)来标识字节序,它的编码是FEFF。这样如果接收者收到FEFF,就表明这个字节流是高位在前的;如果收到FFFE,就表明这个字节流是低位在前的。
比如“汉”字的Unicode编码是0x6C49。
对于大端的文件数据为:FE FF 6c 49
对于小端的文件数据为:FF FE 49 6c
对于大小端的概念,本人经常搞混,什么高地址存低字节的,绕一绕就晕了。下面是我的理解:
- 对于一个16进制数0x1234,我们知道这个数对应的是两个字节,占用16个比特。
- 系统中是按照字节为单位去保存数据的。一个地址空间对应1个字节。比如0x1234如果要存储在计算机里,需要占用两个地址空间。我们假设这个地址空间起始是0x00,因为需要两个字节,所以还需要一个地址空间来保存,即0x01。其中明显0x01是高地址空间。
- 所以问题就在于,对于0x1234这个数据保存,是0x01地址保存0x12还是保存0x24。
- 如果把0x1234看成字符串形式,按照正常顺序存储,先存0x12,后存0x34,对应的就是大端模式。
- 如果按照字节顺序,0x12是高位,0x34是低位,应该0x12存储在高位地址0x02,低位字节0x34存储在低位地址0x01。这种方式就是小端模式。
- 为了怕记混,可以这么记:我最大,按字符串顺序存储,我看的最舒服所以是大端。反面的就是小端的。
| 地址偏移 | 大端模式 | 小端模式 |
|---|---|---|
| 0x00 | 12 | 34 |
| 0x01 | 34 | 12 |
附:代码判断大小端的代码。
原理是生成一个两字节的数据,然后转为1字节的char数据。大端取到的是第一个高字节,小端取到的是第二个低字节。
|
|
UTF-32
详细的本人没看懂,实际中没有用到这个编码,这个编码使用4字节存储。也有大小端之分
总结
- 字符编码就是把可读的字符转化为二进制数据方法,字符解码就是把二进制数据转化为可读的方法。
- ASCII占用1个字节,只有128个字符,主要是英文字符。
- UNICODE是国际标准编码字符集,包含了所有已知符号。
- UTF-8是UNICODE编码的一种实现方式,兼容ASCII码,也就是英文字符占1个字节,汉字可能占两个字节或三个字节。
- UTF-16也是UNICODE编码的一种实现方式,通常和UNICODE编码一致,占用两个字节,分大小端。
Base64编码
Base64编码的作用是把非ASCII的字符转换为ASCII的字符。很多加密算法,很喜欢做一次Base64转换。原因是使用Base64编码后,所有的数据都是ASCII字符,方便在网络上传输。
设计思路是:Base64把每三个8Bit的字节转换为四个6Bit的字节(38 = 46 = 24),然后把6Bit再添两位高位0,组成四个8Bit的字节。所以Base64算法生成的数据会比原数据大1/3左右。
比如:
- 图片这种二进制数据就可以转换为Base64作为文本传输。
- 比如有中文的数据,可以通过Base64转为可以显示的ASCII数据
简单说明:
- 将字符按照文字编码转化为二进制字节。
- 每3字节化为一组(24bit),如果字节不够,最后输出结果补
=。然后再把每一组拆分成4个组,每个组6bit,如果不足6bit后面补0。 - 将每个6bit前面补足两个0,凑够8位。
- 然后按照新分出来的每8位转成10进制数,按照表里面的查找,转为对应的ASCII字符。
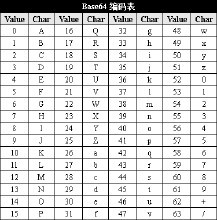
举例:
字符bl如何转化为Base64编码:
- bl对应的ASCII码为:
01100010和01101100,因为只有两个,所以有一个输出结果是= - 按照每三个字节分组:
0110001001101100 - 按照每个组6bit分4个组,不足6位的补0:
011000,100110,110000 - 在前面补
0,凑够8位:00011000,00100110,00110000 - 转为10进制:
24,38,48。 - 查表得到:
Y,m,w - 最后补
=,所以结果为Ymw=
标准的程序实现可以参考:GTMBase64.m。
说明:
Base64是一种编码算法,不是加密算法,他的作用不是加密,而是用最简的ASCII码来传输文本数据,屏蔽掉设备网络差异,是为了方便传输的一种算法。很多加密算法,最后生成的是二进制数据,不是可见字符,而传输的一般是通过字符传输,所以常见的二进制转化方式就是Base64算法。
哈希散列算法
一个萝卜一个坑这个俗语形容这个算法很贴切。官方的定义为:
散列(Hash)函数提供了这一服务,它对不同长度的输入消息,产生固定长度的输出。
安全的哈希算法要满足下面条件:
- 固定长度。不同长度的数据,生成的固定长度的数据
- 唯一性。不同的数据,生成的结果一定不同。相同的数据,每次输出的结果一定一样。
- 不可逆。对于生成后的数据,反推回原数据,通过算法是不可能的。
- 防篡改。两个输出的散列值相同,则原数据一定相同。如果两个输出的散列值不同,则原数据一定不同。
从上面的特点可以知道散列值主要使用的场景:
- 生成唯一的值做索引,比如哈希表
- 用作数据签名,校验数据完整性和有效性。
- 密码脱敏处理。
MD5算法
MD5算法是最常用的散列算法。
对MD5算法简要的叙述可以为:MD5以512位分组来处理输入的信息,且每一分组又被划分为十六个32位子分组,经过了一系列的处理后,算法的输出由4个32位分组组成,将这4个32位分组级联后将生成1个128位散列值。
算法有点复杂,没有看懂,放下不表。
下面是本人的简单理解:
- MD5算法效率是比较快的。
- MD5防碰撞能力比较强,只有少数的几个例子有出现碰撞的情况。但也不影响安全性。
- MD5生成的是固定128位,16个字节。
MD5算法安全性
目前主流看法是MD5逐渐有被攻克的风险。但是目前还没有有效算法破解。
主要的破解方法是使用数据库保存常见的字符串的MD5值,然后通过反查得到原始数据。也就是如果用户的密码很常见就很容易破解。如果用户密码是随机的,那就没什么平台可以破解了。
下面对于是用MD5的观点:
- MD5不是加密算法,重要的用户密码应该加密存储。做MD5只是为了脱敏,也就是不让相关人员知道原文是什么(包括内鬼)。
- 极重要数据是用更安全的算法:比如用户密码数据使用更安全的算法,比如SHA1算法。传输过程中也进一步加密。
- 如果使用MD5算法,在原始值里面加入盐值。盐值要尽量随机。因为如果加入随机值后原始值也变得随机,使用暴力破解就基本不可能了。即
result = MD5(password + salt)
关于加盐
这里有个破解的网站,大家可以看下常用的策略其实都可以破解。安全性主要是盐如何选择。
- 盐值要是随机字符,数据尽量长一些,只有这样才能保证最后数据的随机。
- 盐值尽量保证每个用户不一样,增加破解的难度。
- 盐值的保存可以是前后端约定,固化在APP里,但是也应该和用户相关,比如salt=(固化的值+用户信息)。可以是通过一些随机值变化得来:比如用户注册时间等信息做盐值。可以是每次随机生成,当做参数带给后端,后端保存密码+盐值。安全性从低到高。还有做多次MD5的,个人觉得意义不大。
- 个人推荐的一个方案。
result = MD5 (password + salt)。salt的计算方法是:MD5(Random(128)+ uid)。其中Random(128)表示一个随机128位字符串,两端可以一致,固化在代码里。uid是用户唯一标示,比如登陆用的用户名。这样对于破解者来说就需要先拿到这个salt值,然后对每个用户都要生成一个唯一的128位的盐值,去生成对应的库,破解成本就非常高了。
其实目前暴漏出来的是攻击者把整个数据库的内容拿到后,暴力解密出原文。但是MD5加盐也好变换也好都是可以通过前端代码查到算法的,通过算法就可以生成常用数据对应的MD5库。所以密码做MD5更重要的是脱敏处理,不能做为安全的加密使用,重要的用户密码持久化或传输过程中一定是要通过加密算法处理的。这样只要安全保存私钥就可以了。在很多金融公司,大量使用硬件加密机做加密处理,然后保存,更加大了破解难度。所以如果你的密码是使用加密再保存的,使用固定盐值的已经可以满足要求了。如果担心可以加上用户的注册时间或服务器时间戳做盐值。
SHA1
SHA1也是一种HASH算法。是MD5的替代方案。生成的数据是160位,20个字节。
目前SHA1也被认为不安全,google找到了算法进行了碰撞,所以普遍推荐使用新的SHA2代替。Google已经开始废弃这个算法了。
SHA2
- SHA-224、SHA-256、SHA-384,和SHA-512并称为SHA-2。
- 新的散列函数并没有接受像SHA-1一样的公众密码社区做详细的检验,所以它们的密码安全性还不被大家广泛的信任。
- 虽然至今尚未出现对SHA-2有效的攻击,它的算法跟SHA-1基本上仍然相似;因此有些人开始发展其他替代的散列算法。
所以目前推荐使用SHA2相关的算法做散列算法。
其中SHA-256输出为256位,32字节。
SHA-512输出为512位,64字节。
HMac
HMac是秘钥相关的哈希算法。和之前的算法不同的在于需要一个秘钥,才能生成输出。主要是基于签名散列算法。可以认为是散列算法加入了加密逻辑,所以相比SHA算法更难破解,包含下面的算法。
|
|
HMAC主要应用场景:
- 密码的散列存储,因为需要散列的时候需要密码,实际上相当于算法里加了盐值。使用的密码要随机和用户相关,请参考盐值的生产规则。
- 用于数据签名。双方使用共同的秘钥,然后做签名验证。秘钥可以固化,也可以会话开始前协商,增加签名篡改和被破解的难度。
PS:目前项目中的密码散列算法,采用的就是HMac算法。
总结
- 密码保存和传输需要做散列处理。但是散列算法主要是脱敏,不能替代加密算法。
- 如今常用的Md5算法和SHA1算法都不再安全。所以推荐使用SHA-2相关算法。
- 散列算法应该加入盐值即:
result=HASH(password+salt)。其中盐值应该是随机字符串且每个用户不一样。 - HMac引入了秘钥的概念,如果不知道秘钥,秘钥不同,散列值也不同,相当于散列算法加入了盐值。可以把它当做更安全的散列算法使用。
算法实现
算法都是使用苹果自己的Security.framework框架实现的,只需要调用相关算法就可以了。推荐一个github
|
|
对称加密算法
对称加密,指双方使用的秘钥是相同的。加密和解密都使用这个秘钥。
对称加密的优点为:
- 加密效率高
- 加密速度快
- 可以对大数据进行加密
缺点为:
- 秘钥安全性无法保证,以现在的技术手段来说,默认对称秘钥的秘钥是非安全的,可以被拿到的。
加密方法
- DES :数据加密标准。
是一种分组数据加密技术,先将数据分成固定长度64位的小数据块,之后进行加密。
速度较快,适用于大量数据加密。DES密钥为64位,实际使用56位。将64位数据加密成64位数据。 - 3DES:使用三组密钥做三次加密。
是一种基于 DES 的加密算法,使用3个不同密钥对同一个分组数据块进行3次加密,如此以使得密文强度更高。3DES秘钥为DES两倍或三倍,即112位或168位。其实就是DES的秘钥加强版。 - AES :高级加密标准。
是美国联邦政府采用的一种区块加密标准。
相较于 DES 和 3DES 算法而言,AES 算法有着更高的速度和资源使用效率,安全级别也较之更高了,被称为下一代加密标准。AES秘钥长度为128、192、256位。
使用到的基础数学方法:
- 移位和循环移位
移位就是将一段数码按照规定的位数整体性地左移或右移。循环右移就是当右移时,把数码的最后的位移到数码的最前头,循环左移正相反。例如,对十进制数码12345678循环右移1位(十进制位)的结果为81234567,而循环左移1位的结果则为23456781。 - 置换
就是将数码中的某一位的值根据置换表的规定,用另一位代替。它不像移位操作那样整齐有序,看上去杂乱无章。这正是加密所需,被经常应用。 - 扩展
就是将一段数码扩展成比原来位数更长的数码。扩展方法有多种,例如,可以用置换的方法,以扩展置换表来规定扩展后的数码每一位的替代值。 - 压缩
就是将一段数码压缩成比原来位数更短的数码。压缩方法有多种,例如,也可以用置换的方法,以表来规定压缩后的数码每一位的替代值。 - 异或
这是一种二进制布尔代数运算。异或的数学符号为⊕ ,它的运算法则如下:
1⊕1 = 0
0⊕0 = 0
1⊕0 = 1
0⊕1 = 1
也可以简单地理解为,参与异或运算的两数位如相等,则结果为0,不等则为1。 - 迭代
迭代就是多次重复相同的运算,这在密码算法中经常使用,以使得形成的密文更加难以破解。
对于对称加密来说,有几个共同要点:
- 密钥长度;(关系到密钥的强度)
- 加密模式;(ecb、cbc等等)
- 块加密算法里的块大小和填充方式区分;
加密模式
ECB 模式
ECB :电子密本方式,最古老,最简单的模式,将加密的数据分成若干组,每组的大小跟加密密钥长度相同;
然后每组都用相同的密钥加密。OC对应的为kCCOptionECBMode
ECB的特点为:
- 每次Key、明文、密文的长度都必须是64位;
- 数据块重复排序不需要检测;
- 相同的明文块(使用相同的密钥)产生相同的密文块,容易遭受字典攻击;
- 一个错误仅仅会对一个密文块产生影响,所以支持并行计算;
CBC模式
- CBC :密文分组链接方式。与ECB相比,加入了初始向量IV。将加密的数据分成若干组,加密时第一个数据需要先和向量异或之后才加密。后面的数据需要先和前面的数据异或,然后再加密。是OC默认的加密模式。
CBC的特点为:
- 每次加密的密文长度为64位(8个字节);
- 当相同的明文使用相同的密钥和初始向量的时候CBC模式总是产生相同的密文;
- 密文块要依赖以前的操作结果,所以,密文块不能进行重新排列;
- 可以使用不同的初始化向量来避免相同的明文产生相同的密文,一定程度上抵抗字典攻击;
- 一个错误发生以后,当前和以后的密文都会被影响;
块大小和填充方式
对称算法的第一步就是对数据进行分组,每一个组的大小称为快大小,比如DES需要将数据分组为64位(8个字节),如果数据不够64位就需要进行补位。
PKCS7Padding填充
OC中指定的填充方法只有kCCOptionPKCS7Padding,对应JAVA的PKCS5Padding填充方式。算法为计算缺几位数,然后就补几位数,数值为下面的公式:
value=k - (l mod k) ,K=块大小,l=数据长度,如果l=8, 则需要填充额外的8个byte的8
比如块大小为8字节,数据为DD DD DD DD4个字节,带入公式,l=4,k=8,计算 8 - (4 mod 8)= 4 ,所以补充4个4,补位后得到DD DD DD DD 04 04 04 04。
唯一特别的是如果最后位数是够的,也需要额外补充,比如数据是DD DD DD DD DD DD DD DD8个字节,带入公式,l=8,k=8,计算 8 - (8 mod 8)= 8,所以补位后得到DD DD DD DD DD DD DD DD 08 08 08 08 08 08 08 08。 所以如果考虑补位,实际输出buffer大小要加上快大小,防止buffer不够。
Zero Padding(No Padding)
补位的算法和PKCS7Padding一致,只不过补的位为0x00,比如数据为DD DD DD DD4个字节,带入公式,l=4,k=8,计算 8 - (4 mod 8)= 4 ,所以补充4个00,补位后得到DD DD DD DD 00 00 00 00。
非常不建议用这种模式,因为解密后的数据会多出补的00。如果原始数据以00结尾(ASCII码代表空字符),就没办法区分出来了。
几种算法比较
| 算法 | 秘钥长度(字节) | 分组长度(字节) | 加密效率 | 破解难度 |
|---|---|---|---|---|
| DES | 8 | 8 | 较快(22.5MB/S) | 简单 |
| 3DES | 24 | 8 | 慢(12MB/S) | 难 |
| AES | 16/24/32 | 16 | 快(51.2MB/s) | 难 |
IOS 代码实现解析
下面以AES代码实现为例,说明下IOS加解密算法的实现。
|
|
建议和说明
- 建议使用ECB模式(kCCOptionECBMode),填充采用kCCOptionPKCS7Padding。这种使用最广泛,和PHP、JAVA(AES/ECB/PKCS5Padding)都适配。联调的时候需要注意两端是否一致,不一致是调不通的。
- 通常数据加密后,会做一次Base64编码进行传输,有些应用也会将数据转为二进制字符串传输。
- 如果不指定模式,则默认是CBC模式,需要用到向量IV。
- 如果不指定填充格式,则需要自行补
0x00处理,在解码后也需要把补的0x00去除掉,网上很多资料解码后没有去除,会多出\0。
说明和总结
- 建议对称加密使用AES加密。DES无论安全性和效率都不如AES算法。
- 加密建议用
kCCOptionPKCS7Padding填充方式,对应的JAVA模式为PKCS5Padding - 如果用CBC模式,需要使用初始向量,初始向量两端应该一致。如果不使用应该指定
kCCOptionECBMode。也建议用这个模式,兼容性最好。 - 秘钥应该用随机数生成对应的位数。AES128为16个字节,也就是16个字符。不要用短密码,比如:
111111,这样真的很蠢。 - 对称加密的安全隐患主要在于秘钥的保存。重要会话的秘钥应该随机生成,使用非对称加密来沟通交换秘钥,策略可以参考我的另一篇文章IOS应用安全-HTTP/HTTPS网络安全(一)。
- 如果秘钥需要硬编码到程序里,应该做脱敏运算,比如做位运算进行变形等。后面会专门写怎么解决秘钥硬编码问题。
非对称加密算法
非对称秘钥加密算法的特点是:加密和解密使用不同的秘钥。
非对称加密需要两个秘钥:公开秘钥和私有秘钥。两个秘钥是不同的,而且通过公钥是无法推算出私钥的,使用公钥加密的数据只有用私钥解密。
非对称算法的特点:
- 解决了秘钥保存的问题。公钥可以发布出去,任何人都可以使用,也不用担心被人获取到,只要保证私钥的安全就可以了。而对称加密,因为秘钥相同,客户端泄露了就不安全了。
- 加密和解密的效率不高,只适合加解密少量的数据。而对称加密效率要高。这里有一篇文章对比AES和RSA算法的性能对比。
RSA算法
RSA是目前最常用的非对称加密算法。
算法原理可以看下这篇文章:RSA算法原理。
RSA算法基于一个十分简单的数论事实:将两个大质数相乘十分容易,但是想要对其乘积进行因式分解却极其困难,因此可以将乘积公开作为加密密钥。RSA的秘钥长度在2048位,现有的技术手段是无法破解的(实际的可以暴力破解的位数为768位,也就是768位的大数才有可能暴力进行因数分解)。
RSA算法优点:
- 算法原理简单,我都快看懂了。
- 安全性也足够高,目前没有证据和方案可以破解1048位以上秘钥的RSA算法。
缺点:
- 安全性取决于秘钥长度,推荐的要至少1048位,但是这么高位数的秘钥生成速度很慢,所以没法做一次会话一次秘钥。
- 加解密的效率很低,相对于对称加密,差好几个量级,而且也不支持加密长数据。
国密算法SM2
中国特有的算法,国家强制要求金融机构使用国密算法。包括SM1/SM2/SM3/SM4。其中SM4为对称加密算法。SM3是哈希算法。SM2为非对称加密算法。但是国家只给算法原理,没有给出常用的算法实现,所以是件蛋疼的事情。
算法我也没看懂。因为项目中使用到了,所以做了一些研究。相关代码可以参考我的github,IOS SM2开源实现非常少,而且都有些问题,要么基于openSSL,代码特别大。要么基于libtommath库,但是有一些问题,SM2无法调通。所以两个结合重新整理的下代码。这个代码只保证SM2算法有效性,因为经过实际使用过,其他的项目未用到。
SM2的加密流程
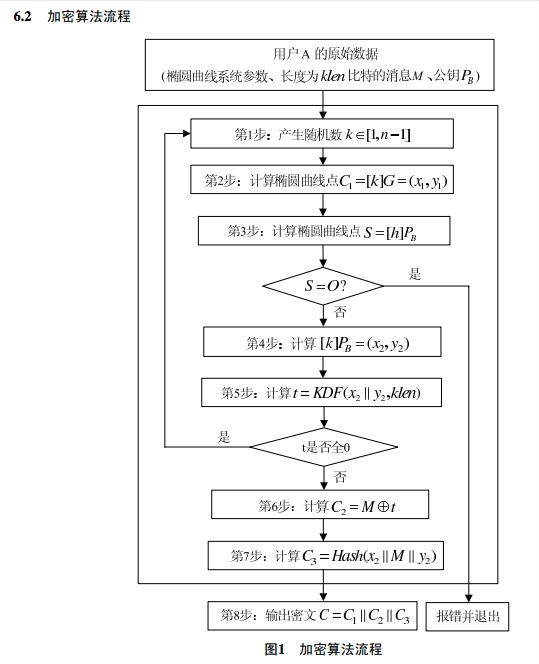
抛出掉数学方法,下面是本人的一些理解:
SM2需要依赖于一个曲线,一般使用国家推荐曲线。如果曲线不对,肯定是无法加解密的。曲线参数
- SM2公钥分为两部分:Pub_x和Pub_y。每个都是32字节,总共是64字节。私钥长度现在还不清楚是多少,有资料说是要32位,但是文档里面未提到。字节数如果不对说明生成秘钥算法有问题。
- 输出数据分为3段:
C1C2C3,其中C1是64个字节,C2和原始数据大小相同,即原文是6个字节,C2就是6个字节,C3是32个字节。所以总长度是64+32+原文长度(字节)。如果长度不对,要看下是否是人为添加了其他字段。 - 算法涉及到哈希算法,标准是使用SM3的hash算法,SM3的Hash算法生成的字节为32字节,这个联调的时候一定要保证一致。
加密步骤说明:
- 第一步计算随机数,如果这个不是随机的,是固定的,那后面的结果每次输出就是唯一的。
- 通过随机数rank和曲线的G_x、G_y、P、A五个参数,通过ECC算法
C1=[k]G = (x1,y1)生成一个点(x1,y1)。拼接起来就是C1数据。C1数据应该是64个字节。有些算法里面会在前面填充0x04,变成65个字节 - 通过公钥的P_x和P_y,随机数rank,A,P,通过ECC算法
[k]PukeyB = [k](XB,YB) = (x2,y2)计算出(x2,y2),x2和y2的大小为分别为32字节 - 将上面的(x2,y2)拼接,然后做KDF(密码派生算法)计算,输出原文长度(klen)的t值。
t= KDF(x2||y2, klen),KDF一般使用的是SM3的算法。结果t的大小和原文的大小一致。 - 然后将t和原文做异或运算,得到C2,C2的大小和原文一致。
- 然后将(x2,原文,x3)拼接,计算一次SM3的Hash算法,生成的数据放入C3中,C3的大小为32字节。
- 最后把
C1C2C3拼接到一起,长度为64+原文长度+32字节。注意,老的标准为C1C3C2,有些实现的是这种模式。
注:这其中ECC算法是标准算法,大部分第三方实现的都没有问题。主要是KDF算法和Hash算法会有不同。这个联调的时候需要搞清楚。
SM2解密流程
流程图如下:
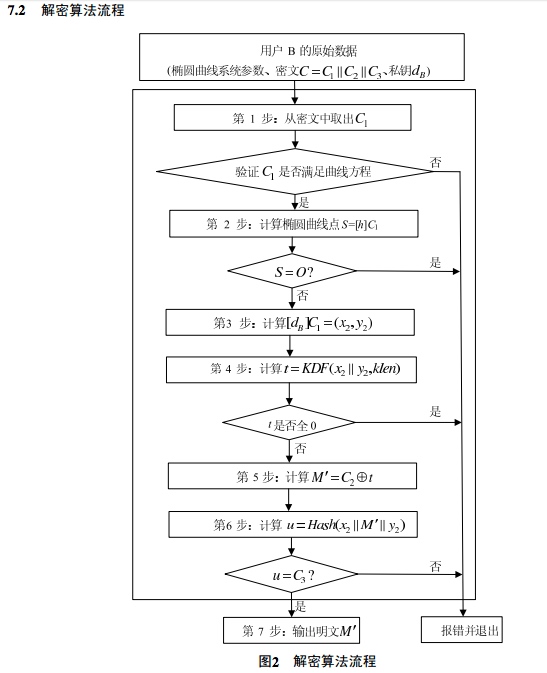
解密步骤说明
- 先判断C1是否在曲线上。C1长度为64字节,取数据的前64字节就可以了。所以两端一定要用同样的曲线。
- 使用C1的数据,曲线参数(A,P),私钥dA,使用ECC算法生成(x2,y2),
dA*C1 = dA*(x2,y2) = dA*[k]*(Xg,Yg) - 使用(x2,y2)和C2的长度(总长度-64-32),使用KDF计算t。
- 使用c2异或t,达到M’
- 计算(x2,M’,y2)的hash值U。
- 比较U和C3数据是否是一致的,如果一致就输出M’
KDF算法说明:
文档里的描述
密钥派生函数的作用是从一个共享的秘密比特串中派生出密钥数据。在密钥协商过程中,密钥派
生函数作用在密钥交换所获共享的秘密比特串上,从中产生所需的会话密钥或进一步加密所需的密钥
数据。
密钥派生函数需要调用密码杂凑函数。
设密码杂凑函数为Hv( ),其输出是长度恰为v比特的杂凑值。
密钥派生函数KDF(Z, klen):
输入:比特串Z,整数klen(表示要获得的密钥数据的比特长度,要求该值小于(232-1)v)。
输出:长度为klen的密钥数据比特串K。
a)初始化一个32比特构成的计数器ct=0x00000001;
b)对i从1到⌈klen/v⌉执行:
b.1)计算Hai=Hv(Z ∥ ct);
b.2) ct++;
c)若klen/v是整数,令Ha!⌈klen/v⌉ = Ha⌈klen/v⌉,否则令Ha!⌈klen/v⌉为Ha⌈klen/v⌉最左边的(klen −
(v × ⌊klen/v⌋))比特;
d)令K = Ha1||Ha2|| · · · ||Ha⌈klen/v⌉−1||Ha!⌈klen/v⌉。
简化下说明:
- 先分组,分组的大小为
klen/v,向上取整,其中klen是数据长度,v是HASH算法输出长度。SM3的输出长度为32字节。 - 然后每一组循环,把原始数据Z和计数器ct拼接,做SM3_Hash运算得到Hai。然后计数器ct+1。
- 最终生成的数据Ha1,Ha2…拼接起来,然后截断到klen长度也就是数据长度。
HASH算法说明
官方使用的是SM3密码杂凑算法,输入为小于2的64次方bit,输出为256bit(32字节)。
总结:
- 国密算法的基础是使用曲线计算。曲线应该使用官方推荐的曲线,曲线不同加解密肯定失败。
- 国密算法生成的数据为
C1C2C3,其中C1为固定的64字节,c2和原始数据一样长,C3为固定的32字节。有些要求数据前面加上’0x04’,旧的版本输出是C3C1C2,这两点要注意。 - 公钥分为P_x和P_y,都是32字节长度。私钥长度从资料上看没有限制,是一个随机数[1,N-2]。N为曲线参数。
- 加密过程中使用了SM3的散列算法(官方叫杂凑算法),这个算法输出为32字节的数据。如果对端没有用这个算法,两端也无法加解密成功。
总结
- 字符编码是为了把可见字符和二进制之间做一层转化。其中UNICODE编码是国际编码标准。UTF-8是这种编码格式的实现方式。特点是ASCII码的字符占用一个字节,其他的比如中文字符占用两到三个字符。
- Base64也是一种编码方式,主要用于把二进制数据转化为ASCII字符,方便传输。现在很多加密算法习惯在加密后把二进制数做一次Base64进行传输。相对于原文,长度会多出1/3。也有把二进制转为字符串的形式,不过长度是原文的2倍。
- 哈希散列算法,主要用于脱敏处理和信息签名防篡改,做哈希运算应该加盐处理。盐值应该是随机值,而且和用户相关,建议使用(随机数 + 用户名)。
- 对称加密两端秘钥相同,加密速度快,可以加密大数据,但是秘钥保存一直是个难题。
- 非对称加密分为公钥和私钥,公钥可以公开。加密速度慢,只能加密小数据,但是只需要妥善保存私钥就可以了。
通常一个信息加密传输流程为:
- 双方约定好使用的编码格式。通常常用的是UTF-8编码。
- 客户端随机生成对称秘钥作为会话秘钥。使用非对称加密传输给后端,后端保存这个对称秘钥用于之后的加解密过程。
- 用户使用对称加密(通常为AES)加密整个数据,结果通常使用Base64做编码(通常还要做一次URLEncode操作),整个相关数据按照规则使用Hash算法(通常为SHA256算法)做数据签名。最后做传输
- 如果是用户密码的话建议用HMac做Hash脱敏处理,然后单独使用非对称加密进一步加强安全性。
